
简单的文献综述-阶段1
¶论文篇目
最近看的三篇论文信息如下图:


三篇论文阅读笔记的链接如下:
《用自监督的对比预测编码进行时间序列变化点检测》个人笔记 | Yangyy’s Life
¶概述
这三篇文章的共同核心就是时间序列异常检测,虽然都是异常检测,但是实际还是有一定差别。前两篇是“Anomaly Detection”,第三篇是“Change Point Detection”,前者是异常检测,后者是变化点检测。异常检测即“不合群”的点,变化点检测就是过渡的点。不过过渡点通常也是“不合群”的点。
¶对于检测方法的预期
三篇论文大致都表达了希望检测方法准确、高效、通用以适应工业界的需求。
¶遇到的困难
当前的检测方法主要分为传统统计模型、监督学习模型、无监督学习模型。
如果数据集的时间序列有足够数量的标签,监督学习(CNN等)其实效果很好。但是在工业界,需要检测的数据集很庞大,手工标记非常困难,所以很少有直接采用监督学习进行预测的。
那么传统统计模型和无监督学习模型虽然不需要手工标记数据,但是实验的效果并不理想。
在”自监督对比预测编码“文章中分析到,对于变化点的检测,传统的统计模型比如根据统计学成本函数最优化,选择合适的变化点(个人的理解就是类似于分段最小二乘法、动态规划)。而且通常是侧重于某些属性/维度。
¶提出的新方法
三篇文章提出的新方法可以概括为“自监督对比预测编码”、“跨数据集检测”、“频谱残差+CNN”。
其实我个人感觉就是尽量贴近监督学习,通过不同的方式,在减少标记数据成本的条件下,达到监督学习的效果。
¶“自监督对比预测编码”——变化点检测
基础的思路:根据历史数据预测未来数据,如果现实数据和预测数据差别很大,说明变异点出现了。但是这种方法通常是针对一个属性,而且和统计分布有关。
自监督对比预测编码:自监督是检测器对每个时间窗口生成一个表征编码(类似于自动标记),预测时就根据时间窗口之间的余弦相似度来判断变化点。
关键就在于表征的生成。采用自动回归的深度卷积神经网络学习编码表示。这里对比预测需要学习相似和相异的属性,因此有正样本和负样本之分,正样本是相似的样本集,负样本是相异的样本集。所以会采集很多连续的时间窗口,子集内部就是正样本对,子集之间互为负样本。设置相应的损失函数即可。
¶“跨数据集检测”
因为监督学习效果好,但是标记成本高,无监督效果又不好。所以可以想到跨数据集检测的方法,基本思路:我们有一些历史的、有标记的数据,而且来自不同领域会有大量的标记数据集,但是因为领域有差别,所以预测新的数据集的时候不能用。但是并不是完全不能用,比如说触类旁通的思想,就是在这些已有数据集上学习到的“知识”,能不能迁移到目标数据集上。直接迁移肯定不行。
迁移学习+主动学习的方法可以。
¶迁移学习
对已有标签的源数据集和没有标签的目标数据集分别进行特征的归纳。特征归纳需要考虑三方面:统计特征、预测误差(多个模型)、时间序列(前后关联)。
归纳之后,对源域进行K-means聚类,因为源数据集可能是不同领域数据集的汇总。然后把部分的目标数据集作为样本,根据欧式距离分配到不同子源域。(这里的问题就是目标数据集不是应该是一类数据吗?)
此后,源域的特征还需要对目标域进行一次对齐(转换矩阵)。
¶主动学习
主动学习的思想就是利用一些目标域的数据进行人为标记,训练源域的检测器。为了尽量选择少并且有代表性的数据,根据不确定性和上下文多样性进行选择。
迁移学习+主动学习得到分类器。最终检测目标数据即可。
作者还控制变量对比了主动学习、迁移学习的组件的工作效果,都很好。
¶“频谱残差+CNN”
首先是希望用无监督的方法得到比较好的检测器。
受视觉显著性检测领域的启发(用光谱残差检测照片或者场景中突出的部分),实际上异常点在时间序列曲线当中也是视觉中突出的部分),所以采用SR进行识别。
¶SR
通过频谱残差分析,可以把时间序列转换成显著图/突出图。
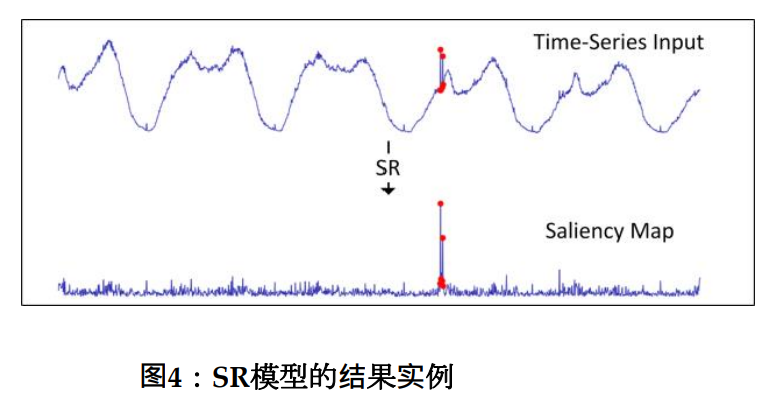
异常点就会更加突出。
在这里其实可以简单根据阈值进行异常点识别了。但是为了更好的效果还是加上CNN。
提到了添加预测点。
¶CNN
因为SR模型已经可以简单输出有标签的数据集了,所以再加上CNN会更好。
首先人为地注入几个异常点。
再CNN。
¶评价指标
允许检测延迟。(有最小时延)
¶总结
三篇论文提出的方法都比各自提到的基准方法有了可以说是全面的提升。
