
《自监督对比预测编码》论文复现
¶前言
本篇文章旨在记录《用自监督的对比预测编码进行时间序列变化点检测》论文的复现过程。
由于本人习惯一边做实验,一边写报告记录,所以文章的撰写也是和实验同步进行的。因此对于能否复现实验成果,我没有很大的把握。但是就算是失败的尝试,也算是值得记录的。
该论文的阅读笔记见
¶要求:

¶正文:
¶1.代码获取
由于是挑选容易找到源代码的论文进行复现,所以这一步并不困难,源码在GitHub上有。
该仓库包含所用的三个数据集中的USC数据集。
¶2.设定参数

根据提示,程序运行需要设定输出路径和输入数据集等参数,提到这两者是必要的参数。
参数可以在PyCharm中设定。(USC是默认的数据集名称)
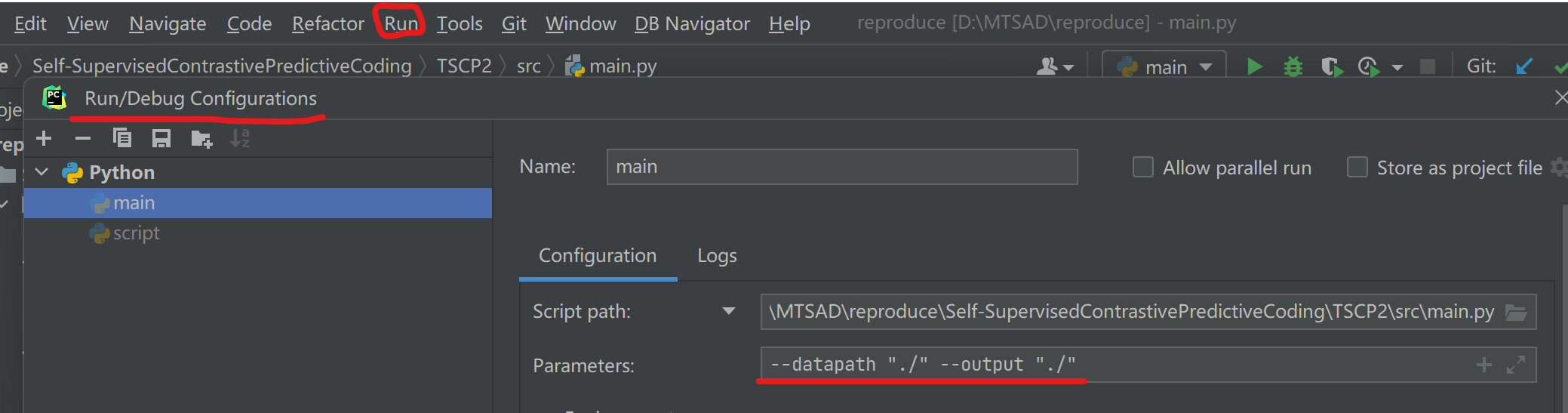
设定参数之后试着运行程序,报错,似乎是因为我的电脑没有GPU资源。
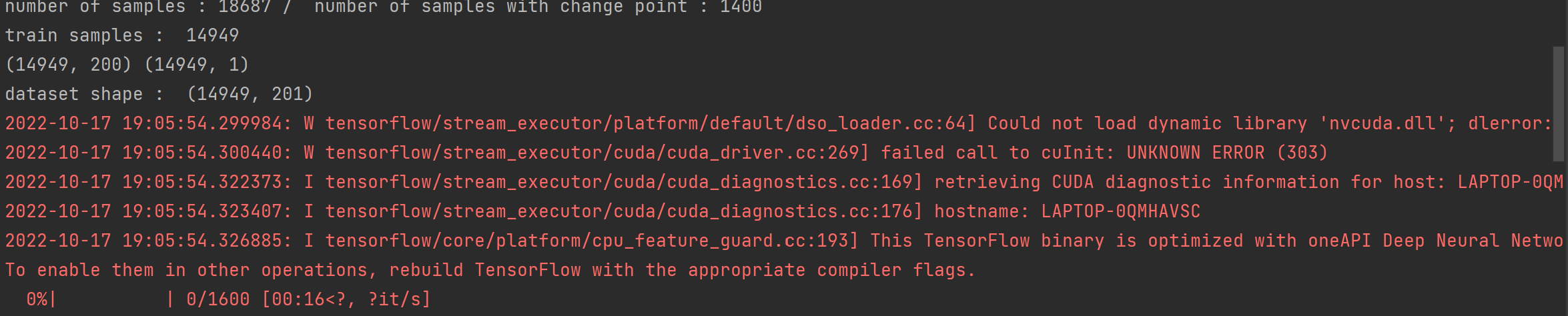
初步判断应该是程序采取CUDA编程,但是我本机不支持,看看能不能修改吧。
后来多等了一会,发现进度条动了

看来是可以跑,只不过也许是因为CPU很慢,所以才显示红色。确实,毕竟也不是报错。
当然,我觉得可能和我把GPU的参数注释掉有关。但是我在整个代码中确实没有发现某个实验过程显式调用了GPU。主要也是我对tensorflow如何选择硬件支持的机制不太了解,也许是它会自主选择,不需要人为设置?
¶3.改用CPU支持tensorflow
这一步暂时没找到合适的解决方案,先放着,尝试结合论文理解代码吧。
(自适应了,不用改)
¶4.理解代码
¶(1)预设置
- 读取外部参数,比如数据集路径,模型存储路径等等
- 设置模型参数,比如时间窗口的大小、批处理大小、迭代轮数等等
- 设置损失函数
¶(2)数据预处理
- 装载数据集,在自定义的DataHelper.py当中有一个load_dataset()函数,参数是数据集所在路径、数据集名称等。(直接完成了数据预处理)
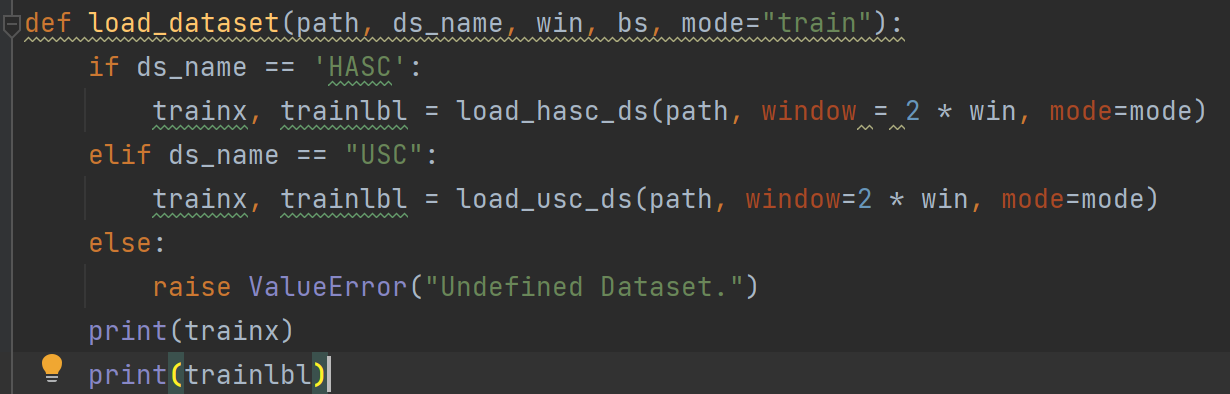
这当中load_hasc_ds和load_usc_ds都是第三方库的函数。
但是这里颇为奇怪,根据代码,如果输入的数据集不是HASC和USC,程序就会报错,那么实验的雅虎数据集是怎么做的?
自己加上打印数据,从而观察输入数据集是什么样的(学长提问)
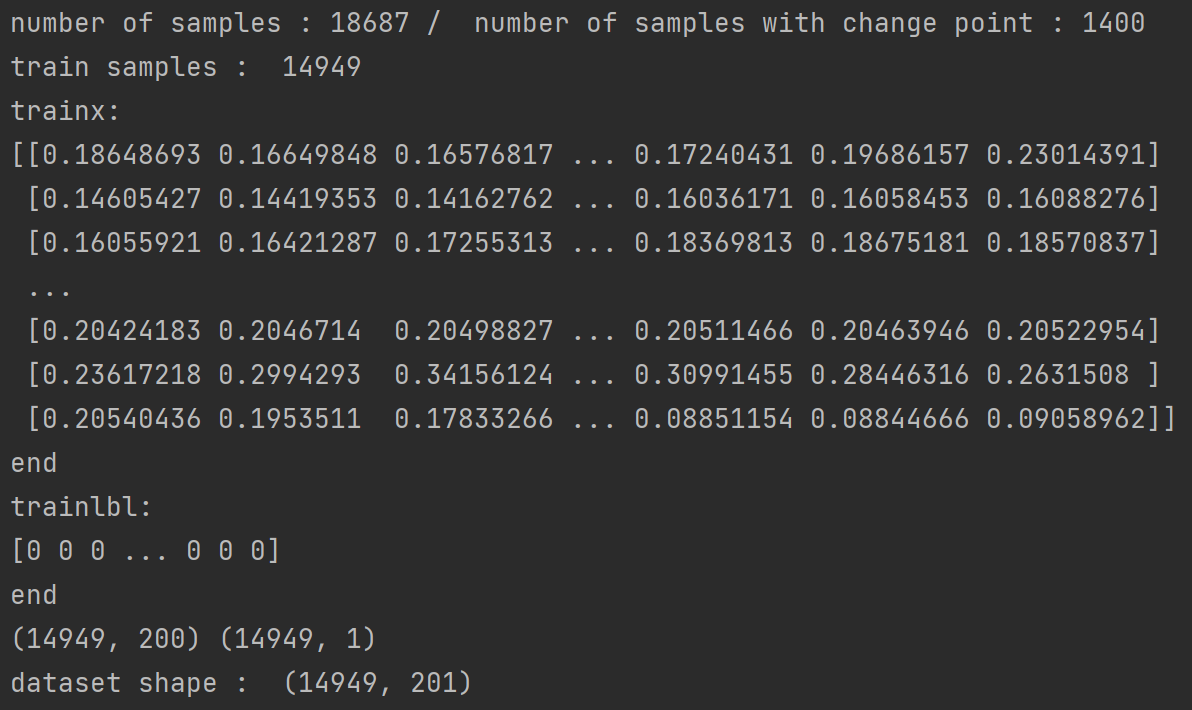
以上信息基本可以反映输入数据集的情况了。
首先总的样本数是18687,其中异常点有1400,大概占比7.5%。
其中选择14949个样本作为训练集,占比80%(常见的比例)。
可以发现输入的数据分为两块,trainx和trainlbl,也就对应着时间序列和是否为异常的标签。
trainx的shape是(14949,200),代表着有14949个样本,维度是200维,代表着200个属性。
而trainlbl的shape是(14949,1),代表着14949个样本,每个样本对应1维的0/1值,代表是否为异常值。
因此输入的数据集的shape是(14949,201)。
可以看看最初始的数据集长什么样
就是非常长的一串数据,应该是未经切分处理的时间序列数据。
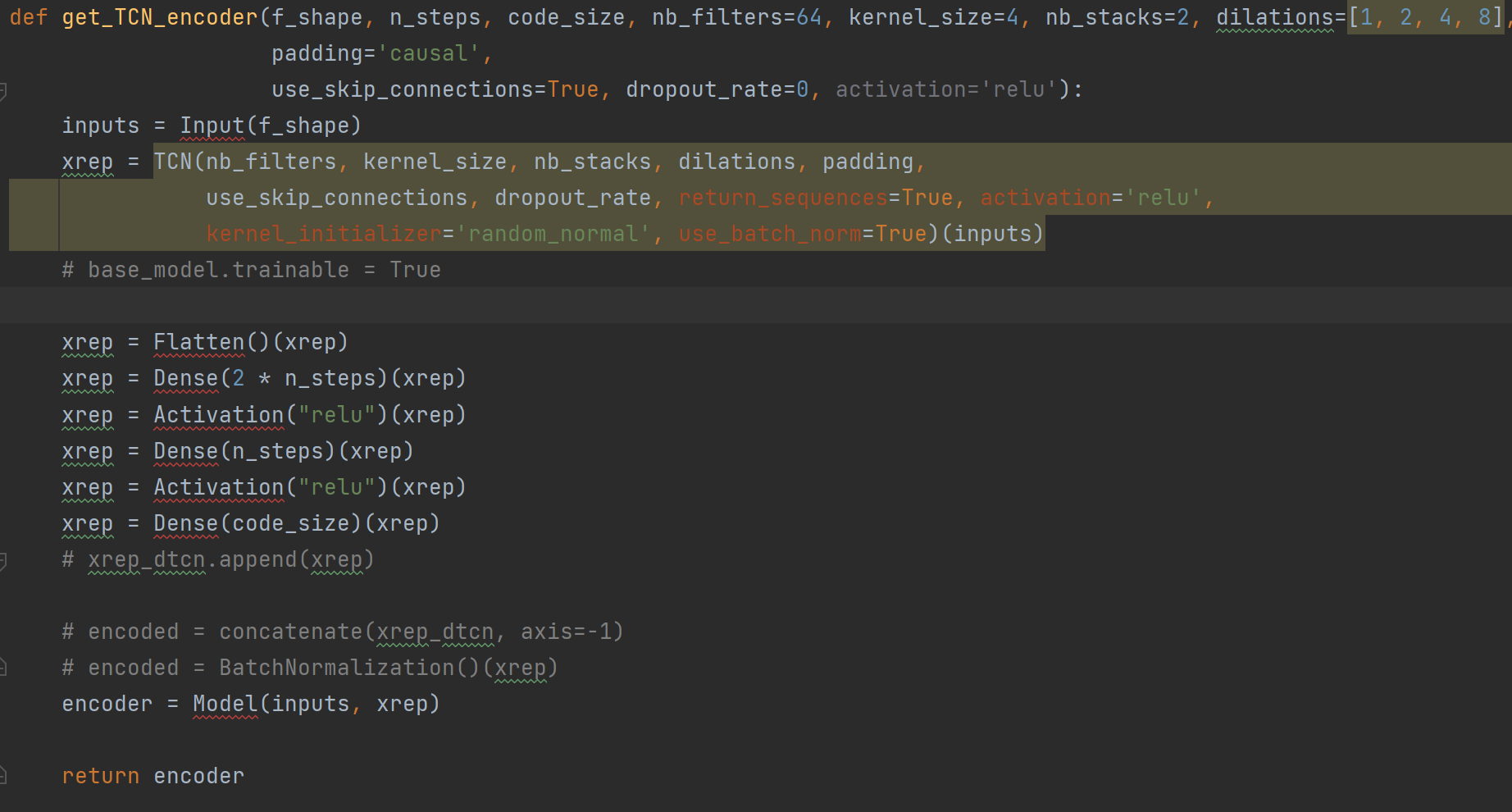
¶(3)构造特征编码器的基本结构
TS-CP2方法的核心是编码器。这里主要定义其结构。
¶(4)训练得到编码器
训练的目的就是得到编码器的合适参数,也就是得到合适的编码器。类似于神经网络里的神经元的参数。
过程采用对比预测编码(正样本集和负样本集的各种对比获取信息)
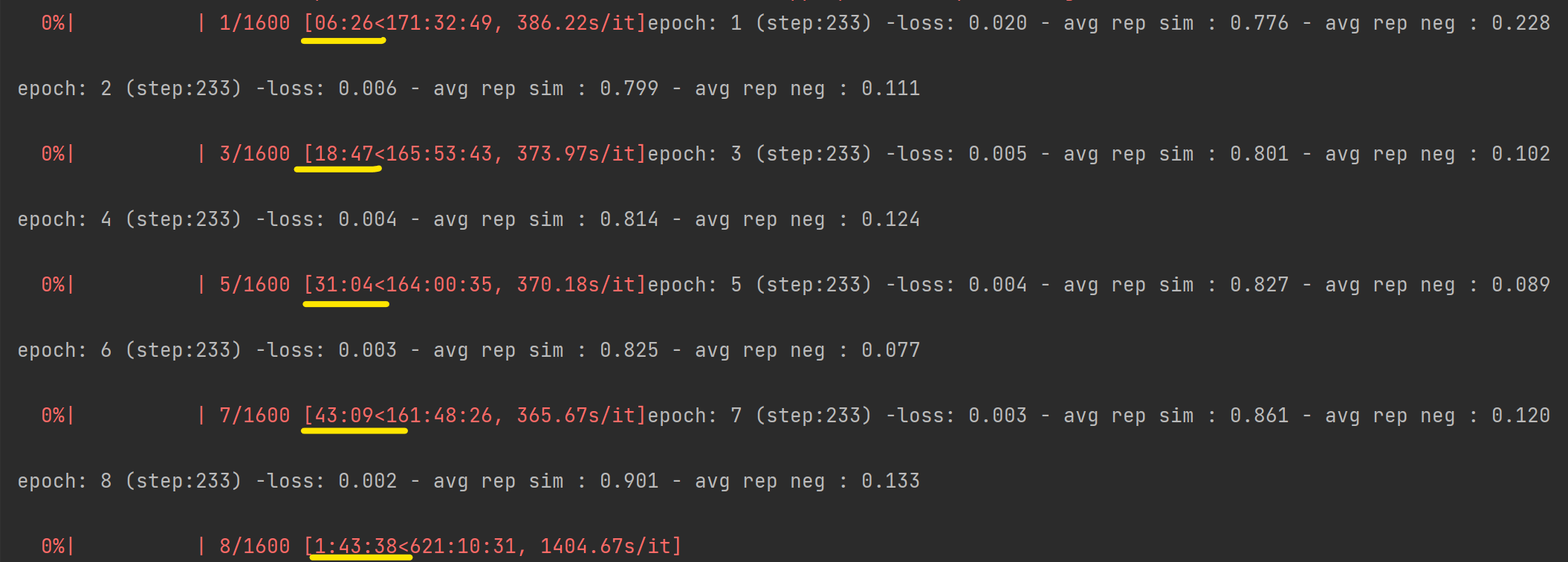
用CPU进行训练非常漫长,而且每轮迭代的用时迅速增加,第6轮迭代到第8轮迭代用时1小时,花了近两小时训练过程仅未完成8/1600,所以没能完成训练模型的过程。
根据代码可以发现,编码器输出的编码特征的大小是可以指定的参数,默认是10。意味着向编码器输入时间序列,每个时间点得到一个10维的特征编码。
1 | parser.add_argument('--code', type=int, default=10, help='size of encoded features') |
¶(5)进行测试
¶1)装载测试数据集
¶2)输入到特征编码器
¶3)根据特征编码计算余弦相似度
¶4)根据余弦相似度判断是否异常
如何计算异常分数?异常阈值是多少?
1 | def estimate_CPs(sim, gt, name, train_name, metric='cosine', threshold=0.5): |
异常分数用余弦相似度衡量,异常的阈值也是需要指定的参数(默认就是0.5)。
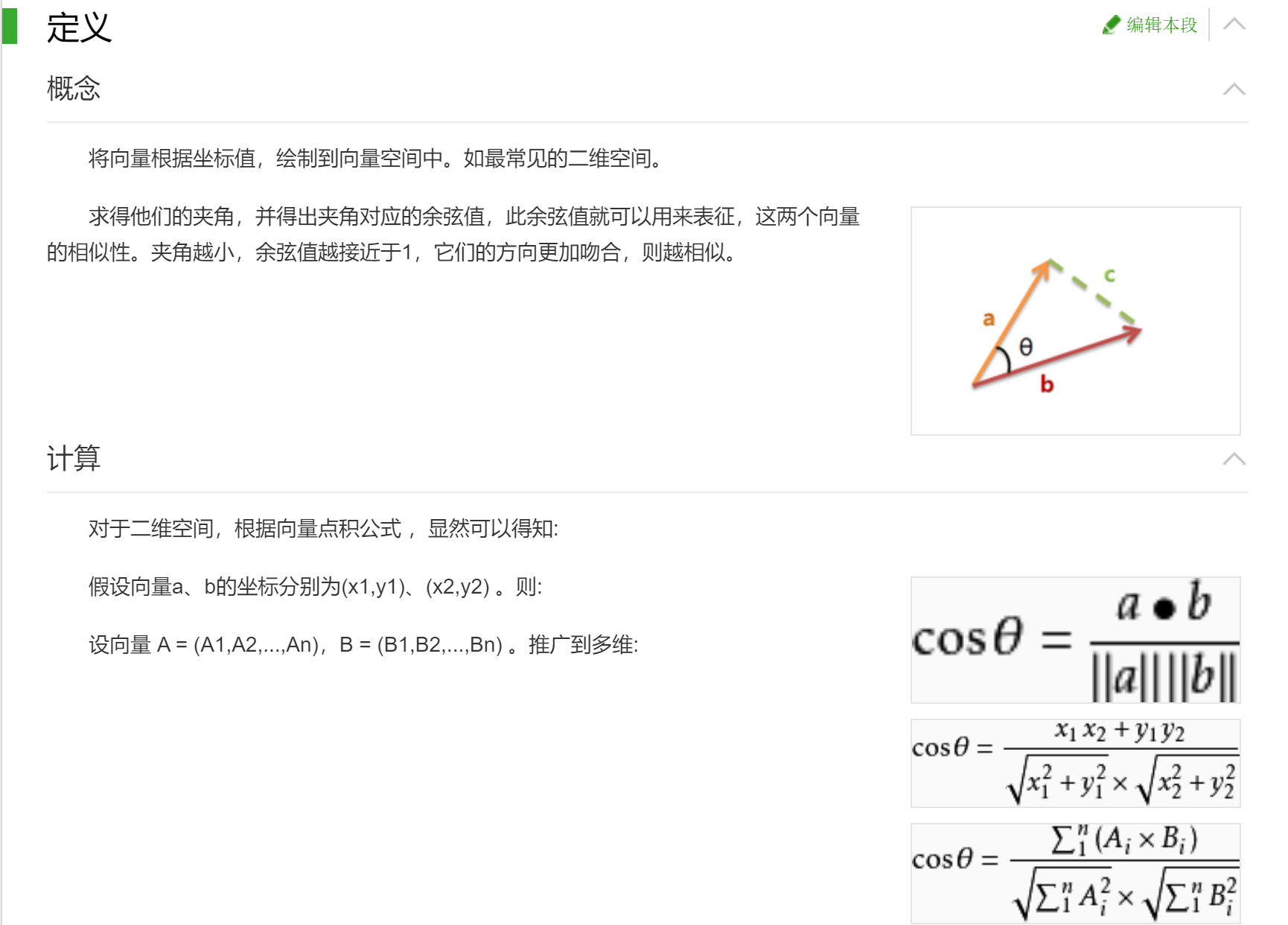
余弦相似度的相关知识:

但是阈值这一参数也是需要计算(正负样本集)得到的:
1 | threshold=epoch_wise_sim[-1] - ((epoch_wise_sim[-1]-epoch_wise_neg[-1])/3) |
最终输出就是0/1序列,代表是否为异常点。
¶(6)保存模型
结语:总体摸清了实验的思路,但是有的具体细节还没能理解,限于机器算力,未能完整复现实验。
