
二刷TSCP2论文
¶前言
TSCP2模型来自论文《Time Series Change Point Detection with Self-Supervised Contrastive Predictive Coding》,译作《用自监督的对比预测编码进行时间序列变化点检测》。
其实这篇论文我已经阅读过,并且“复现”过。这篇论文是我接触科研的第一篇论文(已经是四个月之前的事了)。当时对科研工作的了解几乎为零,所以实际上阅读和复现都不甚规范,了解异常检测及其方法的目的倒是达到了。
四个月后虽然我科研能力并没有提升多少,了解也并没有增加很多,但是好歹比此前进步了。主要也是课题组需要复现一些MTS AD的方法,进行效果的对比。此前由于没有GPU资源,只是简单地跑了一下。这次实实在在地复现一次,记录一下效果。
¶正文
¶二刷论文
¶摘要
CPD识别与时间序列数据的趋势和属性变化相关的时间以描述系统的基本行为。
提出一种基于对比预测编码的自监督的时间序列变化点检测方法——TS-CP2。
TS-CP2是第一个在CPD中使用对比学习策略的方法,通过将相邻的时间区间与跨时间区间的嵌入表征的对比实现。
证明优于五个最先进的CPD方法(包括无监督和半监督)。
¶简介
大量处理能力和存储容量的提供意味着我们目前拥有前所未有的访问和分析数据的能力。数据存储和共享的规模、速度意味着缺乏数据整理。数据注释昂贵。因此自监督和无监督学习很火热。
CPD是一种识别突变的时间点的方法。
变化点可以为系统基本行为提供重要理解,比如变化点代表系统状态的改变和故障或者紧急情况的发生。
CPD被广泛应用于多变量时间序列数据,以及其他具有时间特征的数据模式。
变化点通常是从时间序列的不同属性中的一个来估计的,包括时间连续性、分布或形状。无监督的CPD方法通常是为了识别某一个特定属性的变化而开发的。
目前CPD方法未能有效推广,因为不同应用的语义边界通常与不同的事件序列属性相关。比如心电图的时间形状模式体现心脏节律异常、统计特征的突然变化可以体现人类姿势的变化。用统计学的CPD检测心电图,性能就会下降。
缓慢变化的时间形状和统计属性也是一个挑战。
因此提出了TS-CP2。提出问题:自我监督学习是否可以为CPD提供一个有效的、通用的表示。直觉是利用时间序列的局部相关性,学习一个表征,使连续时间区间共享信息最大化,使分离的时间区间共享信息最小化。相邻时间区间学习到的表征有明显不同就可能出现变化点。
¶相关工作和背景
¶时间序列变化点检测
目前CPD的方法大多是基于非深度学习方法。现有的方法可以根据变化点检测考虑的时间序列的特征来分类。
1、统计学方法通常在确定的时间序列中相邻短区间的统计差异的基础上计算变化点。区间之间的统计差异通常用参数或者非参数的方法测量。
2、还有一类统计学的CPD方法,将变化点确定为分段边界,通过动态编程、贪婪搜索等方法使得统计学成本函数最优化。
3、利用时间序列的时间形状模式,通过识别时间序列中与形状模式突出变化相关的未知检测变化点。
4、混合的CPD方法,利用时间序列的时间形状模式和统计分布。
5、基于深度学习的CPD方法最近也被提出来了。
6、CPD在视频处理应用也非常实用。
¶表征学习(自监督表征学习)
¶对比学习
对比学习是一种使用一组由正面样本对和负面样本对组成的训练实例来制定数据集中样本相似或不相似的原因。
¶基于对比的表征学习
前面这些都属于比较宽泛的概括性知识,建立起对CPD领域的大致了解即可。
主要还是学习TS-CP2模型的具体方法论。
¶方法论
¶问题定义
给定多变量时间序列**{X1,X2,…,XT}有T个观测值,Xi∈Rd**。试图估计与时间序列属性变化相关的时间t。未来表征和预期表征的异同可以看作过渡到下一个片段的措施。
¶TS-CP2概述
有一些异常检测方法使用自动回归模型进行预测,在这些方法中,变化点是在与预测误差显著增加相关的样本中检测出来的。
建议使用表征学习提取紧凑的潜在表征,其对原始数据分布不变。
论文采用类似CPC的方法来学习使连续时间窗口之间相互信息最大化的表示方法。
首先,一个自动回归的深度卷积网络WaveNet被用来对每个时间序列窗口进行编码;其次,在编码的基础上采用一个3层的全连接网络产生更紧凑的嵌入表征。连续时间窗口的嵌入表征之间的余弦相似度被计算出来以估计变化点。
对比学习的方法被用来训练编码器,in each batch用一对连续的时间窗口和一组跨越时间的窗口对。
¶表征学习
TS-CP2方法的核心就是编码器,将连续的时间窗口转换成紧凑的嵌入表征。通过最大化相邻时间窗口的交互信息训练该表征以学习短时间尺度上的相似性。
使用WaveNet而不使用LSTM。
具体的编码器的架构就不复述了,主要就是将时间窗口映射到低维度空间。
其实最主要的是如何训练编码器,我们输入一对正样本和一组负样本,关键还是设计好成本函数。
¶成本函数
采用**InfoNCE loss function**。
计算每个批次的阳性样本对概率:
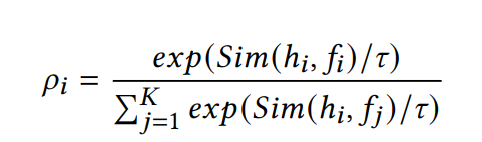
Sim代表计算余弦相似度。t是缩放参数。
损失函数:
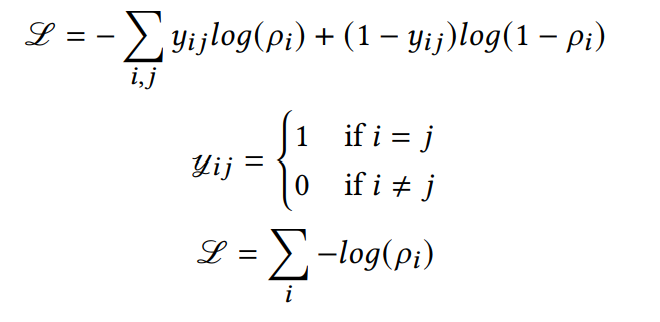
¶负向采样
随机抽出阳性样本对,用于构建每个批次的阴性样本对。
基本原理如下图所示:
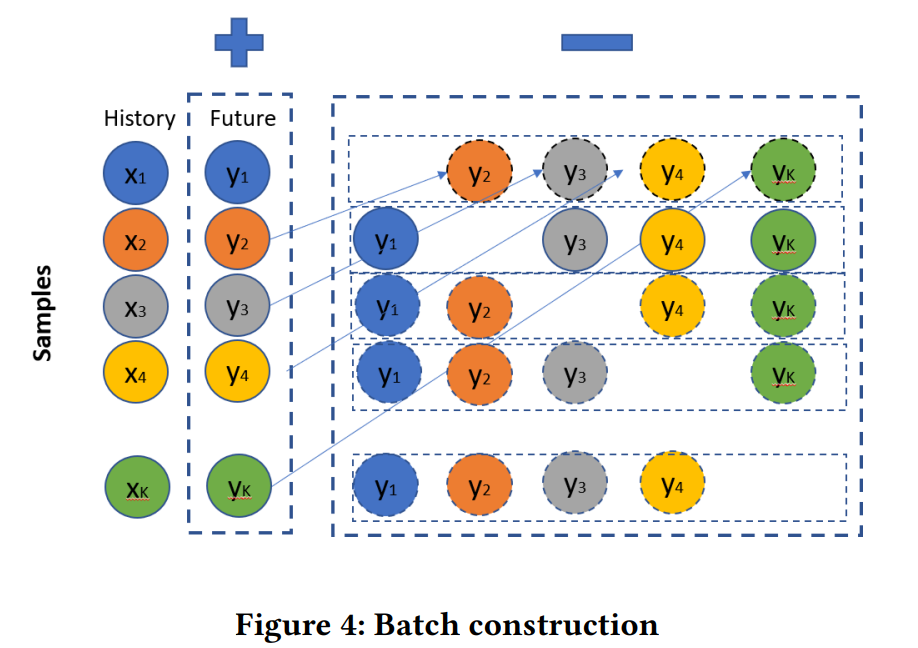
个人理解:
选出K个相邻的时间窗口对(x1, y1)、(x2, y2)、…、(xk, yk),但是每一对时间窗口之间的时间间隔要足够长。这样一来:
x1和y1构成正样本对,(x1, y2)、(x1, y3)、…、(x1, yk)就构成一组k-1个负样本对。
因此k个连续时间窗口,实际上生成了k组训练实例。
简单又巧妙!
¶变化点检测模块
现在已经完成了编码器的构建以及训练的设计,理论上编码器已经能够实现较好的自监督效果了,接下来的问题就是如何检测变化点了。
将成对的历史和未来窗口转换为嵌入表征,计算余弦相似度;和平均值做差;用寻峰算法寻找差值函数的局部最大值,与之相关的点通常被认为是变化点。
¶实验
(来到了最重要的实验阶段。一方面实验才是真正的任务需求(作为基线方法对比;另一方面实验能使得我更好地理解论文idea的真正落实)
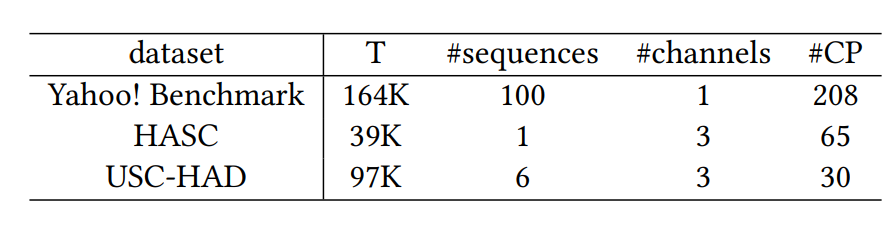
¶数据集
分析方法在各种应用中的有效性:网络服务流量分析、人类活动识别和移动应用程序使用分析。
- 雅虎基准数据集是最广泛引用的异常检测基准之一。(网络服务流量分析)
- HASC挑战赛的数据集。(多个传感器收集的人类活动数据集)
- USC-HAD。也是收集人类活动的数据集。
¶Baseline方法
提出的TS-CP2方法的性能与五种最先进的**无监督**变化点检测技术进行比较。
- ESPRESSO
- FLOSS
- aHSIC
- RuLSIF
- KL-CPD
¶评价指标
模型性能以F1 Score来评价。
注意!注意!变化点的检测是有误差范围的,而不是直接对比标签和预测结果的。比如t1是变化点,t2不是;预测的结果是t1不是,t2是;不一定是预测错了两次,如果t1和t2间隔在允许的误差范围内,那么我们会认为这次预测是正确的。
¶微调和敏感度分析
主要分析TS-CP2对以下方面的敏感性:
-
Window size。窗口大小,也就是历史和未来间隔的长度。这个数值不宜大也不宜小,并且通常由数据集决定。
较长的时间窗口拥有最高的F1分数。
-
Batch size。也就是前面提到的数值K。在4~128之间。
通常情况下,批量大小和检测性能之间有一个单调的递增关系。
-
Code size。编码长度。就是输出的嵌入表征的维度,在4~20之间。
最佳代码大小取决于窗口大小和批大小
¶Baseline Comparison
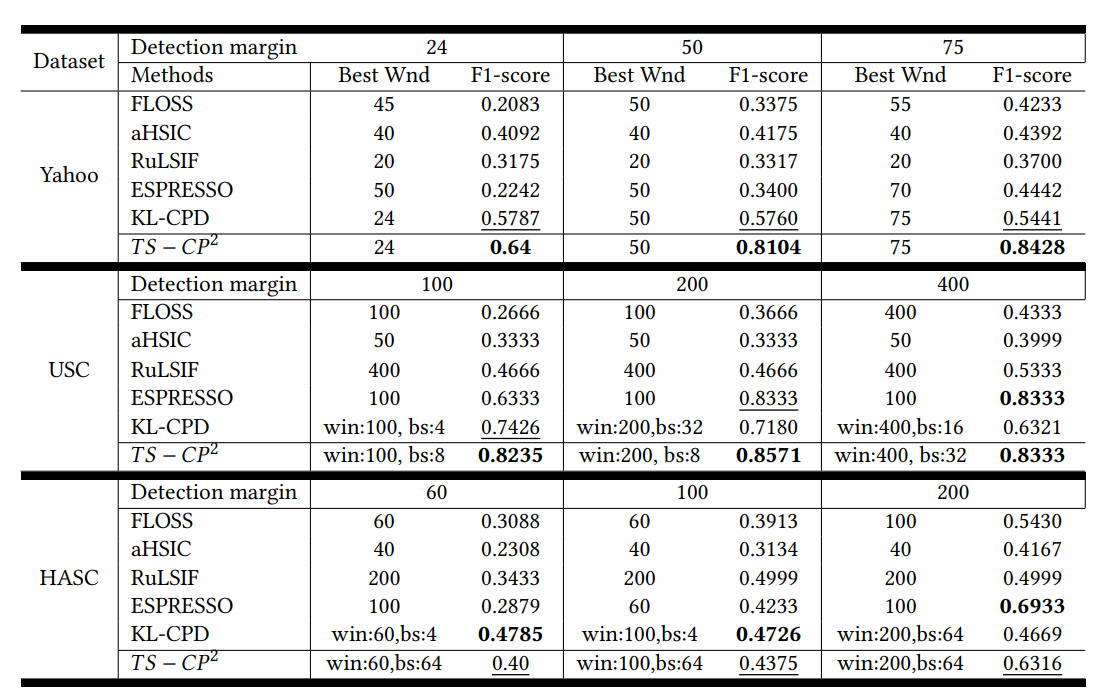
非常非常重要的一个优势在于:
TS-CP2模型一旦训练出来,CPD的实现就非常简单,只涉及到历史和未来窗口的学习表征之间的比较(余弦相似度的计算),很可能在低资源设备上实现在线操作。基准方法不能在线应用。
¶复述论文核心思想
本文的名字叫用于时间序列变化点检测的自监督对比预测编码,我认为核心就是两个点:**自监督**和对比。
实际上时间序列异常检测如果有充足的成本进行异常点的标注(也就是标签的生成),那么用监督学习的方法效果会非常好(之前看的论文当中提到的)。但是由于这个成本太大了,不现实,所以大家被迫探索统计方法和无监督学习的方法。
本论文说的自监督就是自我生成表征(类似标签的作用),因此需要一个编码器。但是由于缺乏标签,我们没有实际值来验证编码的效果。所以引入了第二个重要的点,对比学习。也就是通过相邻的时间窗口和远隔的时间窗口学习正面和负面的信息(生成样本的负向采样方法也十分有趣)。因此采用了InfoNCE计算损失函数进行学习。学习得到一个良好的编码器之后,可以通过计算相邻时间点的余弦相似度进行变化点的检测。
最终变化点的验证还会涉及到误差范围的设置。
以上完成了论文的阅读,接下来开始复现模型效果。
¶复现模型效果
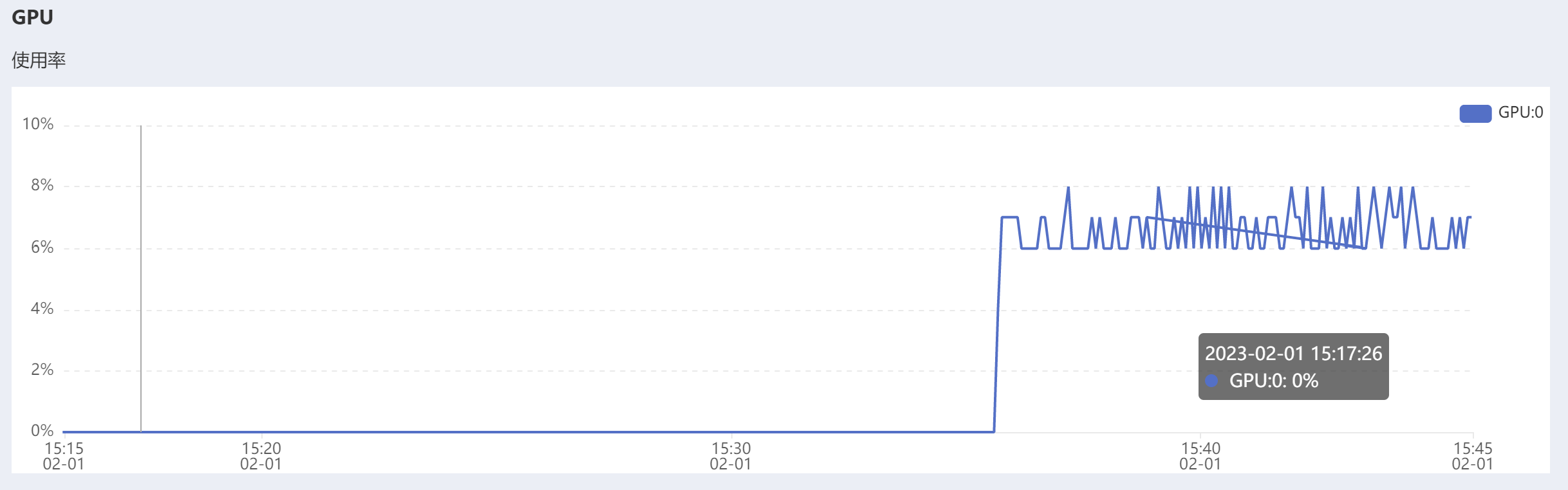
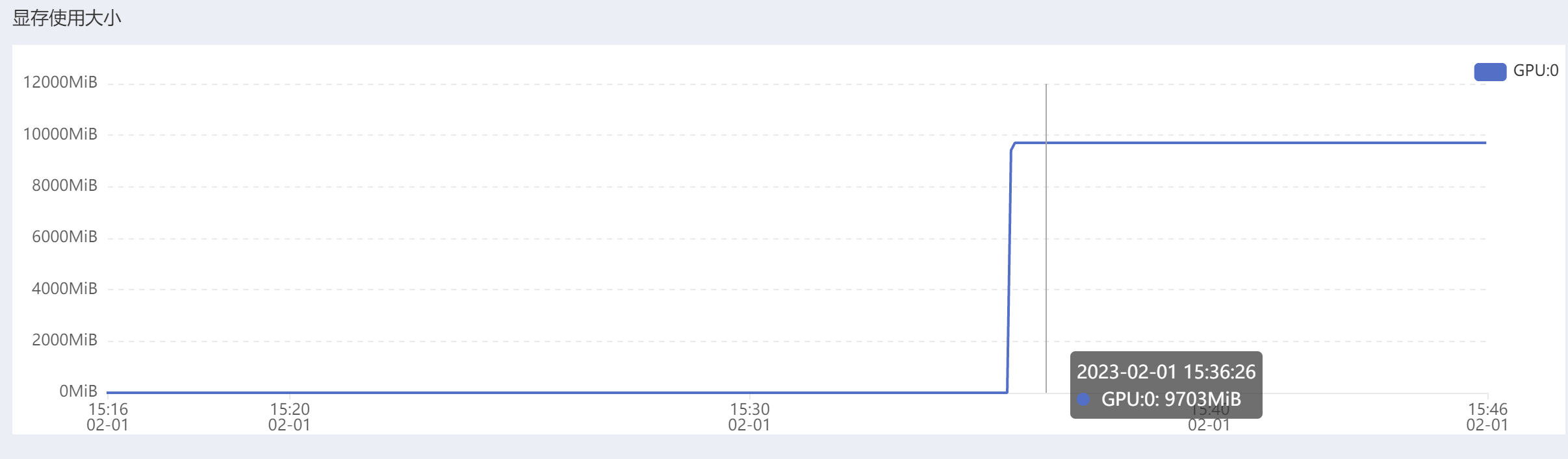
可以发现,在训练的过程中:显存的利用率非常大,但是GPU的利用率却不到10%,非常奇怪。
看到一种说法是“如果图片的分辨率太大,即使一张图片(batch_size为1)放入显存,也直接爆了,GPU利用率当然也无从谈起,外在表现就是显存几乎占满,但同时GPU等不到数据,一直空闲。解决方法是将图片分辨率改小就OK了。”
我把batch_size从64调整为16,显存还是撑满,GPU使用率降低了
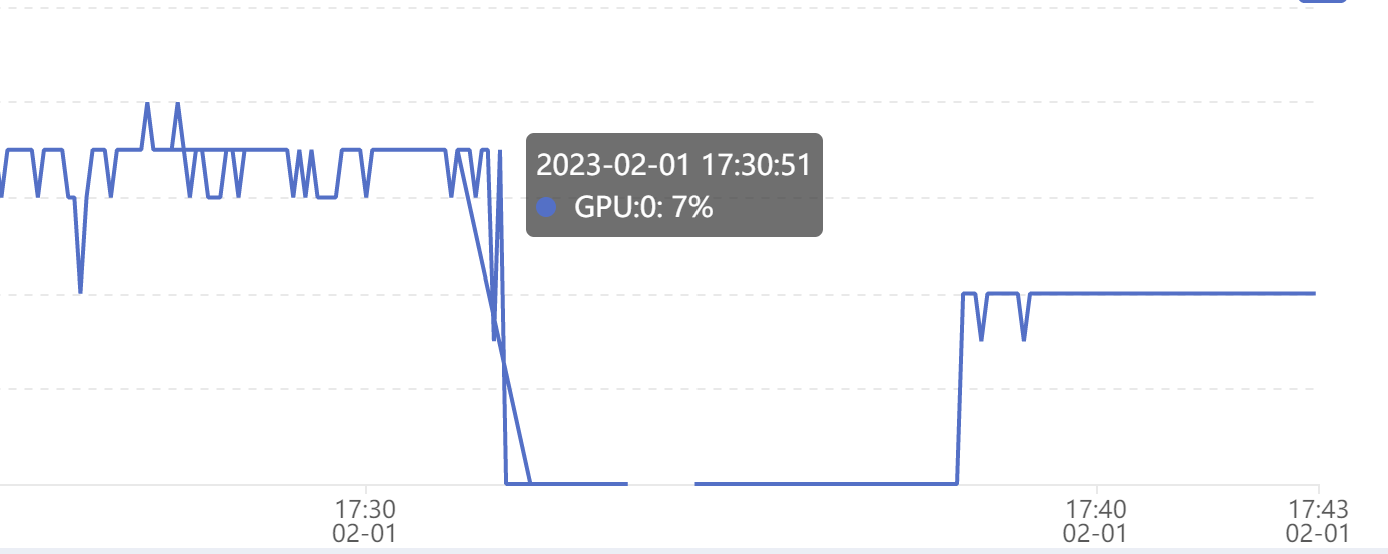
利用率反而只有一半了。
再把batch_size从16调到256
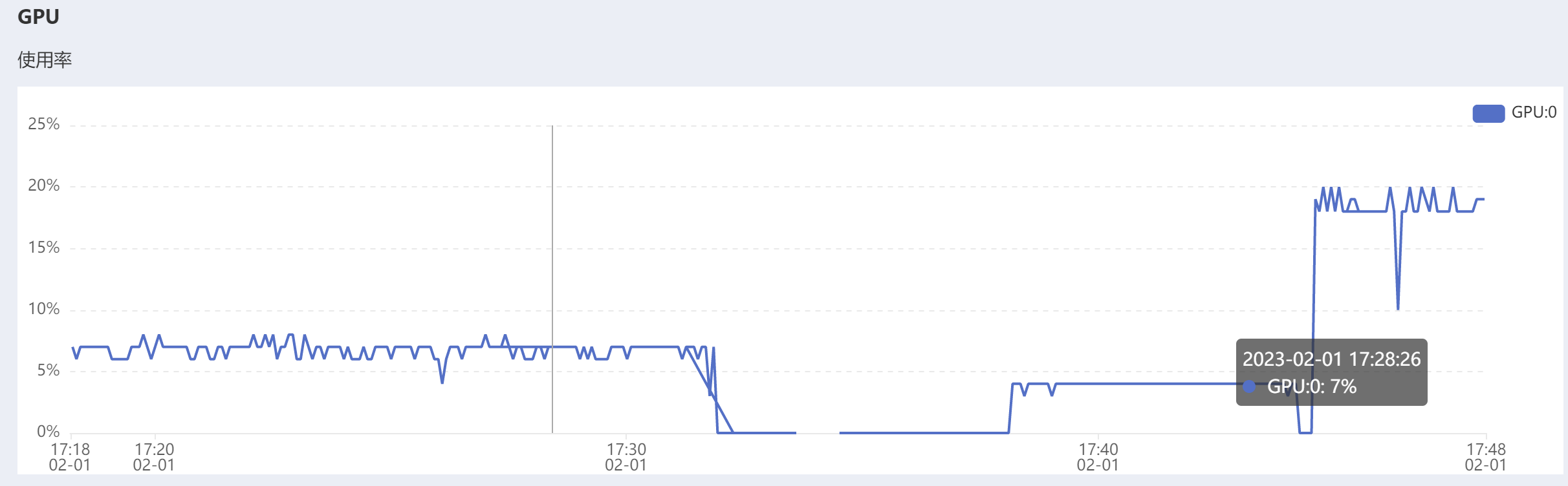
GPU使用率大幅度提高。但是预计训练用时没怎么变化(还是需要20小时左右,CPU是621个小时😥)属实离谱。
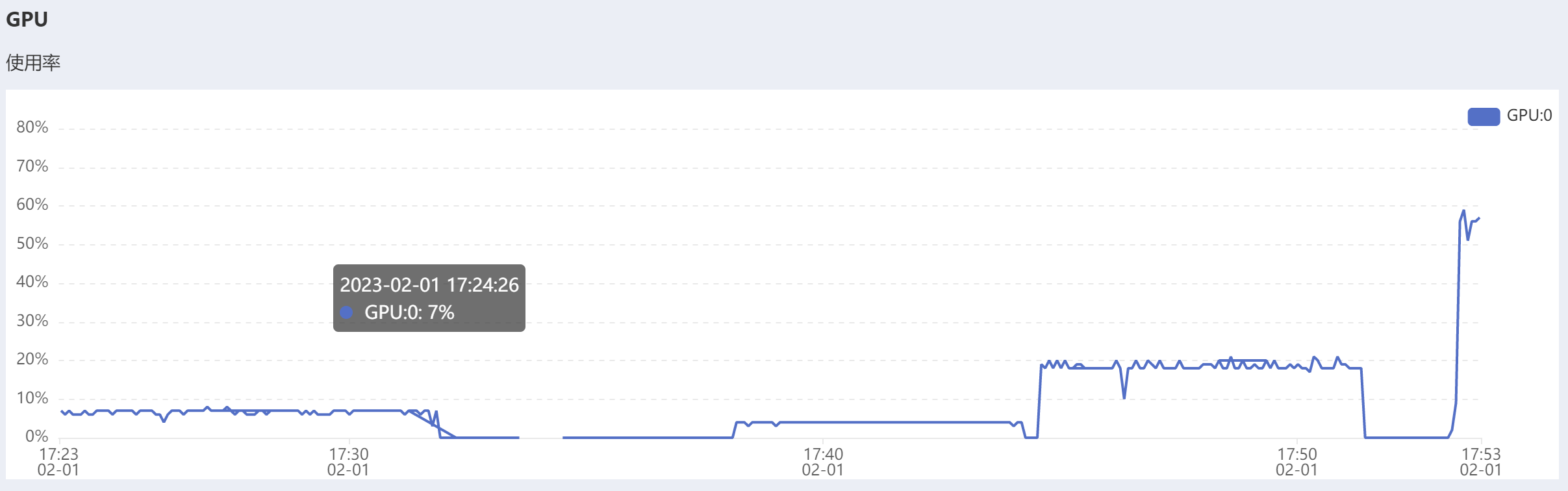
果然batch_size越大使用率越高,1024的时候已经到了60%左右了,提升了10倍,反正显存都是撑爆。但是总时间还是19小时啊。
总共时间点的数量就是T,不会反复训练,大抵是epoch = batch /4,然后会随机在一定时候停止一下训练,进行验证。验证之后会存储模型。
修改了一处代码错误:
原代码:
1 | history = prep_model(x_test[:, 0:WIN].reshape((num, 1, WIN))) |
但是这样会报错
1 | Traceback (most recent call last): |
所以按照提示,我将代码修改为
1 | history = prep_model(x_test[:, 0:WIN].reshape((num, WIN, 1))) |
这样代码就可以跑通了。
可是我是原封不动地clone整个项目的呀,为什么会出现这样的问题,原作者没有遇到吗?
但是因为训练非常短暂,所以
¶终于知道为什么训练会提前终止了
因为它设置了提前终止条件
1 | if epoch > 5: |
就是训练五轮以上时,连续出现四次以上的loss没有明显变化或者loss反而增大了,那么就会停止训练。
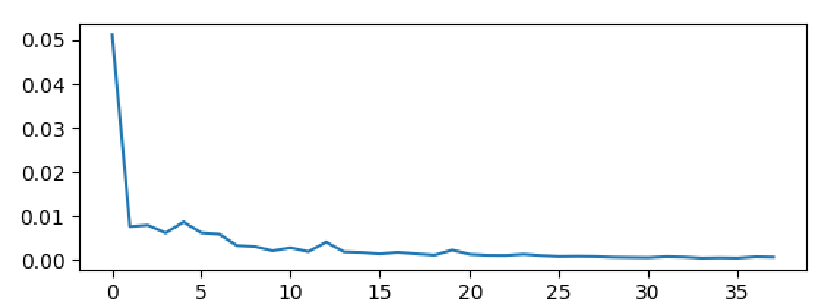
看训练过程中存储的Loss曲线,确实一下子降下来之后就不怎么变化了,所以很早就终止了。
但是目前的F1 score非常低,只有0.4,不知道为什么。
主要是不能按照论文的batch_size跑,那样要很久(毕竟是自己花钱租服务器),为了提高GPU利用率,我只能提高batch_size,但是这样可能就没法复现效果。
loss确实是很快就降下来了。
论文中最佳效果对应的batch_size是8,但是这样的话GPU利用率只有3%左右,训练非常慢,不知道效果怎么样。
但是训练中loss很低,sim很高,neg也比较低,看起来效果是不错的,为什么F1就不好看。
¶2/1的收获:
今天主要是改了两个bug,模型可以正常运行了
也发现了batch_size和GPU利用率的规律
但是没法达到论文中说明的效果。
¶2023/2/2 总结一下当前的进度以及遇到的问题
阅读论文熟悉TS-CP2模型。
找到官方源代码尝试实现论文中描述的效果。
clone的官方源代码会报错,进行了修改,目前模型可以正常运行。
问题:
现在复现的方法是不是之后论文中对比实验的基线方法?我自己随便选的会不会不合适。
目前没有达到论文中提到的效果有两方面原因:
1、利用的数据集是比较小的简化数据集(为了节省实验时间)
2、论文中最佳实验效果的batch_size大小是8这样的较小数字,而GPU的使用率和batch_size之间有类似单增的关系,batch_size=8是GPU的使用率只有3%左右,训练模型的预计时间很长。如果提高batch_size,GPU的使用率能得到提升,但是训练的效果不太理想。
¶学长对问题的回答
1、复现的方法不一定需要很高大上,主要是能通过对比实验看出我们的方法的效果是不是更好,可能在其中再挑一些方法作为baseline methods,所以自己找比较top的会议当中提出的论文进行复现就好了,最后就是要能转换到我们自己的数据集上。复现论文最重要的是要能把模型转换到我们自己的数据集上!!!
2、模型效果调不到理想也是十分正常的,基本上都很难调试到论文中描述的效果。
