
学习DCN模型
¶前言
DCN模型由论文《Deep & Cross Network for Ad Click Predictions》提出。本次对DCN模型的学习也就是对该论文的阅读。
¶补充
阅读论文到一半突然对这两篇关于DCN模型的论文有些开窍了。不管是DCN模型还是DCN-V2模型,他们都服务于广告点击率的预测,大致的任务也就是输入一则广告的相关信息(包含各类特征信息),我们的模型应该输出对于其点击率的预测。个人认为,这种任务和输入图像、输出分类结果没什么区别。所以其实一开始也就是采用DNN(深度神经网络)这种模型,只不过效果不算好,因此改进,加入交叉网络而已。
¶论文阅读
¶简介
点击率(Click Through Rate,CTR)预测是一个大规模问题。
在广告业中,广告商向出版商付费,流行的支付模式是每次点击的成本。因此,出版商的收入很大程度依赖于准确预测CTR的能力。
**识别经常预测的特征同时探索少见的交叉特征**是做出好的预测的关键。但是网络规模的推荐系统的数据大多是离散和分类的,导致特征空间大而稀疏。限制采用线性模型。
引入一种新的神经网络结构——交叉网络。该网络以自动的方式明确应用特征交叉。
联合训练交叉网络和深度神经网络。
¶深度和交叉网络DCN
在本节描述深度和交叉网络(DCN)模型的架构:从一个嵌入和堆叠层开始,然后是平行的交叉网络和深度网络,最后是组合层,将两个网格的输出结合起来。如下图所示:
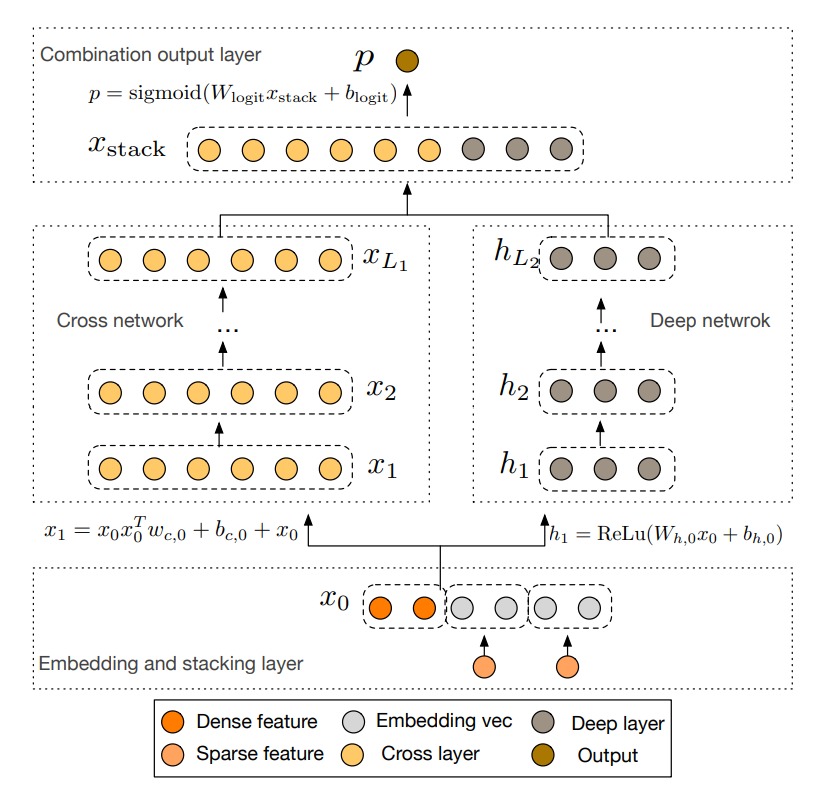
¶嵌入和堆积层(Embedding and Stacking Layer)
考虑具有稀疏和密集特征的输入数据。输入的数据大多是分类特征,例如“country=usa”,这样的特征也会变**编码为独热向量,如[0, 1, 0],但是这样会导致特征空间很高**。
为了降低维度,采用一个**嵌入程序,将这些二进制特征转化为密集的实值向量(嵌入向量)**。
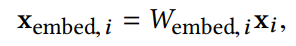
其中Xembed,i是嵌入向量,xi是第i类的二进制输入,Wembed,i是相应的嵌入矩阵,嵌入矩阵会随其他参数一起被优化。
最后,嵌入向量于归一化的密集特征堆叠(stack)成一个向量x0。
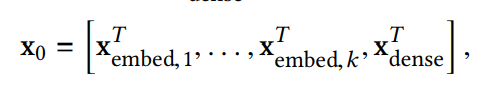
¶交叉网络
交叉网络的关键思想是**以一种有效的方式应用显示的特征交叉**。
交叉网络由交叉层组成,每层有以下公式:
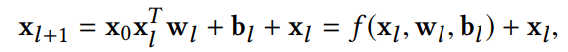
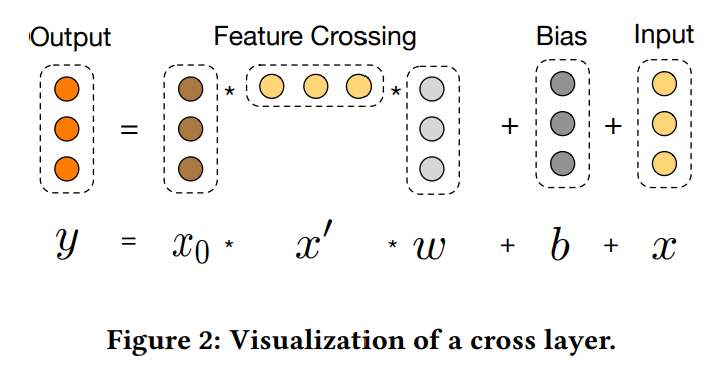
交叉网络的参数数量少,限制了模型的容量,为了捕捉高度非线性的相互作用,引入一个并行的深度网络。
¶深度网络
深度网络的结构相比其他的深度神经网络的结构会更简单一些,是一个**全连接的前馈神经网络**,每层有以下公式:
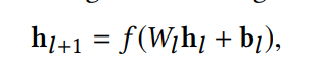
¶组合层
组合层将两个网络的输出连接起来,将串联的向量送人标准的logits层。
以下是一个二分类概率的公式:
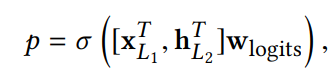
其中XL1是交叉网络的输出,hL2是深度网络的输出(二者转置之后串联起来成为一个向量),Wlogits是组合层的权重向量,相当于两个一维向量点积得到一个数,仍然会输入σ(x)=1/(1+exp(-x))。
损失函数如下:
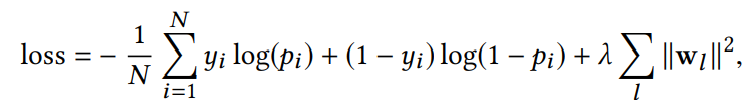
yi是真实标签,pi是计算出的概率。
但是为什么输出的是概率?不是应该是点击率吗?还是说点击率也按区间转化成了标签?
¶交叉网络的分析
主要就是分析DCN当中,交叉网络的有效性。
这里暂时也不太看得懂。
¶实验结果
这一节主要是评估DCN的性能。
¶Criteo数据集
Criteo数据集是为了预测广告的点击率,有13个整数特征和26个分类特征,每个类别都有很高的cardinality。因此对于这个数据集而言,0.001的logloss都是很有意义的。
该数据集包含7天(约4100万条记录),使用前6天的数据用于训练,第七天的数据随机拆分为同等大小的验证集和测试集。
¶实施细节
官方的代码是用TensorFlow实现的。
¶结语
论文的大致阅读就到这里了,对于复现模型而言,性能测试和基线方法的比较可以暂时不谈,毕竟支撑的知识还是太少太少。接下来开始具体的复现这个DCN模型吧。
