
通过论文学习DAGFM模型
¶前言
本次科研实习的任务是利用RecBole框架复现论文《Directed Acyclic Graph Factorization Machines for CTR Prediction via Knowledge Distillation》中的DAGFM模型,因此第一要务是把论文学习明白,把模型熟悉清楚。再开始琢磨如何利用RecBole进行复现。
¶正文
译作《用于点击率预测的利用知识蒸馏的有向无环图分解机》
¶摘要
网络规模的推荐系统中高维稀疏数据增长,在CTR预测任务中学习高阶特征交互的计算成本大大增加。
一些基于知识蒸馏的方法将知识从复杂的教师模型转换成浅层的学生模型,加速模型推理。但是知识蒸馏会导致模型精度下降。如何平衡浅层学生模型的效率和效果是一个挑战。
为了解决这个问题,我们提出一个有向无环图分解机(DAGFM),通过知识蒸馏从现有的复杂交互模型当中学习高阶特征交互,用于CTR预测。提出的轻量级学生模型DAGFM可以从教师网络当中学习任意明确的特征交互,实现近似无损的性能,通过动态编程算法得到证明。改进的模型DAGFM+可以有效地从任何复杂的教师模型中提炼出显性和隐性特征的相互作用。效果甚佳。
¶简介
点击率(CTR)预测的目的是预测用户点击某个项目的概率。CTR预测中实现良好性能的关键是学习有效的高阶特征交互。最大的挑战之一是原始特征的高阶交互建模的高计算成本:原始特征数量增加之后,特征组合的数量会指数增长。原始特征本身通常都是高度稀疏的(标识符特征被编码为one-hot向量之后很稀疏、从上游任务(视觉信息)建立的多文件向量也是),再在此上计算高阶特征交互非常耗时。
需要一种轻量级的CTR预测的推荐算法简化在线推理过程,从而避免实际行业中计算成本爆炸。
目前有一些努力,利用知识蒸馏(KD)技术将知识从复杂的教师模型转移到学习参数减少的浅层的学生模型,加快模型推理速度。但是降低学习参数的KD模型的代价是模型精度下降。
提出一个轻量级的基于知识蒸馏的DAGFM预测CTR。设计一个具有较少学习参数的影子学生模型,但是保持现有的复杂交互模型提取高阶特征交互的能力。
具体地说,有向无环图当中每一个节点代表一个特征域,不同节点通过不成环的有向边连接。节点间的连接,代表特征的交互,用DAG中的边的可学习权重(毕竟不同的特征交互作用是不一样的)来模拟。通过特定的交互学习函数(内部、外部、内核),DAG上的特征交互作用可以转化为明确的任意顺序的交互。
为了从隐性特征交互模型(AutoInt、FibiNet)中提炼知识,进一步改进DAGFM,多层感知机(MLP)被集成进去,因此DAGFM+可以学习任何显性和隐性的特征交互。
¶Preliminary(初步的?知识预备?)
首先介绍CTR预测任务,然后介绍其中的显性高阶特征交互和交互学习函数。
¶CTR预测
点击率预测就是预测用户点击某个项目的概率(给你用户信息和项目信息)。具体说,就是给定m个特征字段,用x={x1,x2,…,xm}表示用户和项目特征。标签y∈{0,1}代表是否点击。根据x进行预测。CTR预测任务中,取得良好性能的关键是学习有效的高阶特征交互。
¶高阶特征交互
给定输入特征x={x1,x2,…,xm},x的嵌入特征表示为{e1,e2,…,em}(向量降维)。
显示特征交互可以表示为
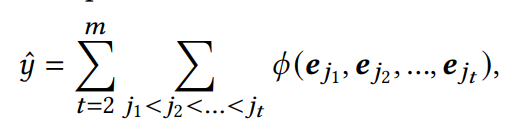
∅代表特征交互函数。
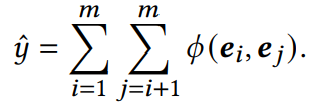
(这两个公式还是比较好理解的)
¶交互学习函数
特征交互学习函数定义了计算特征间交互作用的方式。不同的交互模型使用不同的交互学习函数。
-
基本的内部交互学习函数。
现有研究中最常用的交互学习函数表述为:
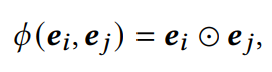
代表element-wise product(Hadamard product),含义是两个矩阵对应位置元素进行乘积。其实就是向量点积。
-
加权的内部交互学习函数。
上述方法不能捕捉到不同场景的特征信息(因为所有特征交互都一视同仁了),导致梯度耦合问题。为了解决这个问题,提出了许多场景感知的变体,使用权重参数来模拟不同场景的特征交互作用。
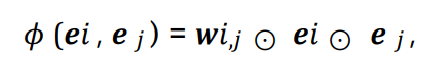
wi,j是i和j的权向量。
-
内核的交互学习函数。
通过扩展权重向量的维度,最近的研究提出了更为强大的交互学习函数:
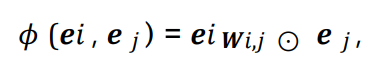
Wi,j是学习权重矩阵。
纳入了交互权重之后,有了很大的改进。但是模型的复杂度也大大增加,列举所有不同场景权重的高阶特征交互是NP问题。大多数现有的高阶特征交互模型通过增加参数来提高模型能力,但是代价是极高的计算成本,显然不太符合实际。
-------------手动分割线,去外婆家吃午饭
-------------我又回来啦,下午继续干活
¶方法论
为了低计算成本下提高模型性能,提出了一种基于知识蒸馏的有向无环图分解机,其中一个轻量级的学生模型有向无环图分解机设计来从现有的复杂的教师模型当中学习高阶的特征交互。
¶有向无环图分解机
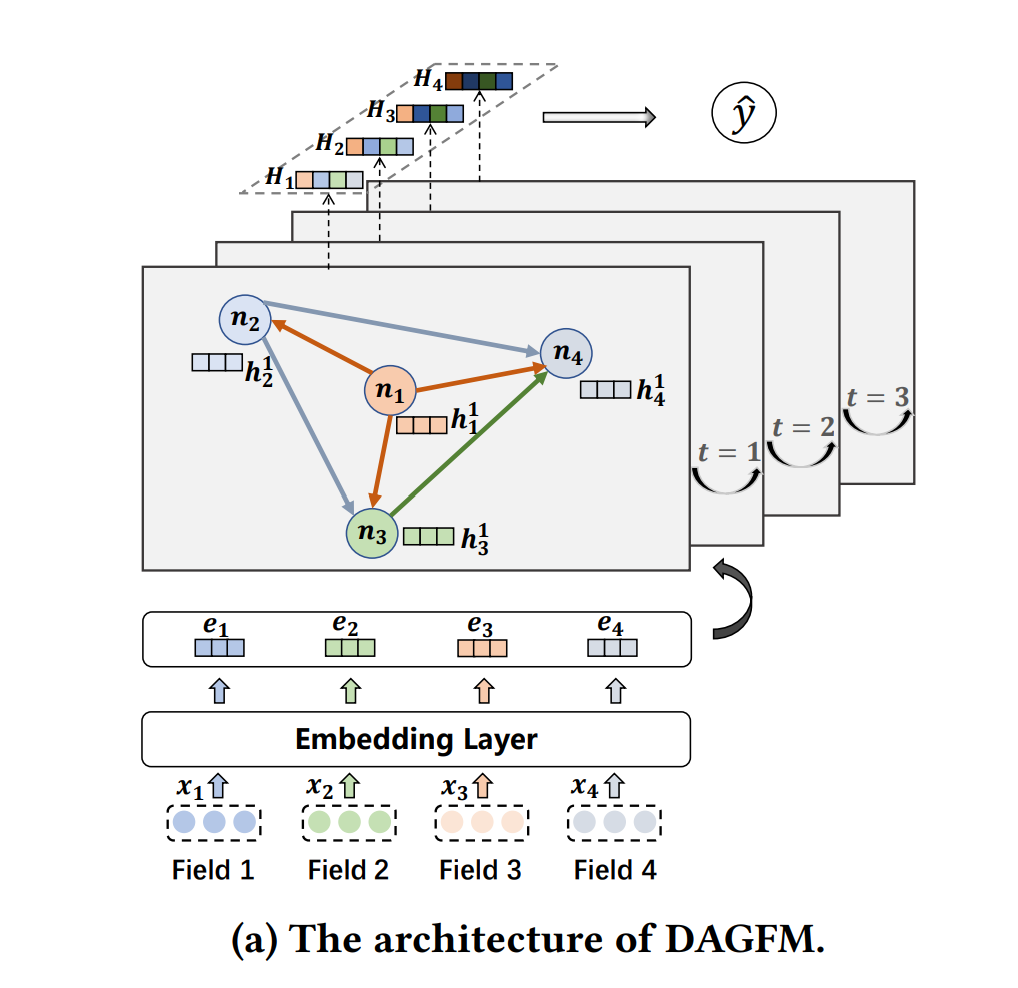
设计的轻量级学生模型就是有向无环图分解机DAGFM。结构如下图。先介绍其构造和信息交互过程,然后介绍提出的高效外部交互学习函数。
-
DAG的构建。
如架构图所示,给定输入特征x={x1,x2,…,xm}。嵌入层将输入的特征从A到B映射出去(高维稀疏空间到低维稠密空间、ei=xiWi)。
有向无环图定义为G=(N, E)。其中每个节点ni∈N对应一个特征域,|N|=m。每个节点ni的初始状态设置为ei,即h1i=ei。节点ni到nj(j>i)的边是有指向的,控制着不同特征域的交互权重。
-
在DAG上学习特征的交互。
特征之间的交互可以以递归的方式建模为DAG上的**信息传播过程**。在每一个传播层,每个节点都会汇总来自邻居的状态与自身的初始状态h1i来更新状态向量。形式上,传播层t的节点ni表示为:
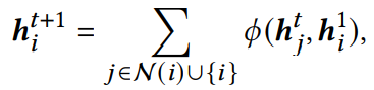
初始层t=0。其中N (𝑖) = { 𝑗 |𝑛𝑗 → 𝑛𝑖 ∈ E},也就是j∈i和指向i的所有节点,𝜙 是交互学习函数。
为了获得用于CTR预测的高阶特征交互信息,首先在每个交互步骤对每个节点的隐藏状态向量应用了sum pooling
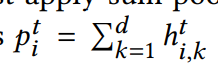
其中ht(i,k)表示hti的第k个元素。其实就是向量元素全相加(因为d是embedding size)。
计算完毕之后,把第t层的所有节点的这个值连起来,形成
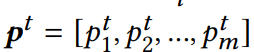 不同阶的特征交互就表示为p=[p1;p2;…;pl],传播层的数量为l-1。
不同阶的特征交互就表示为p=[p1;p2;…;pl],传播层的数量为l-1。最后用于CTR预测的函数表述为
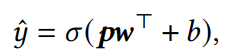 σ是sigmoid激活函数,w是转换向量,b是偏置。
σ是sigmoid激活函数,w是转换向量,b是偏置。 -
外交互学习函数
DAGFM的特征交互学习函数𝜙很灵活。可以利用最常用的内交互学习函数,也可以用模型能力更强的内核交互学习函数。
为了降低内核交互学习函数的计算复杂度,提出了一个简化的外部交互学习函数。
内核交互学习函数中的学习权重矩阵是:
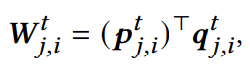
p、q都是分解向量。
(我个人的理解是比如权重矩阵是m×n的,权重矩阵内部的元素肯定是学习得到了,那么初始化的时候可以用分解向量1×m和1×n矩阵乘得到m×n。实际上矩阵是d×d的)
那么外部交互函数就可以定义为
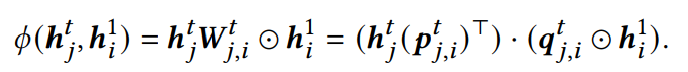
前者是1×d × d×1,后者是1×d · 1×d,把复杂度从O(n2)降到了O(n)。
-------------手动分割线,继续学习
¶DAGFM当中任意阶的交互学习
本节证明了在DAGFM中学习到的特征交互与动态编程算法中不同的唯一加权路径相一致,显示了DAGFM学习任意阶特征交互的能力。
我们将一个**特征交互的后缀定义为具有最大下标的特征**。比如特征交互:e2e3、e3e4e5,其后缀分别为e3和e5。
让Sti表示所有以ei为后缀的t阶特征交互。以以e3为后缀的2阶特征交互为例,S23={e1e3,e2e3,e3e3},以ei为后缀的1阶特征交互e1i={ei}。
在动态编程算法中,hti就是sti内元素的累加。事实上,所有以ei为后缀的t+1阶特征交互可以被表示为ei和(以ej(j<=i)为后缀的t阶特征交互的交互)。
因此状态转移方程可以改写如下:
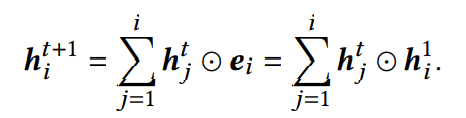
(这个公式应该还是比较好理解的)
在DAGFM当中,特征的交互是基于有向无环图进行传播的,节点ni的另据N(i)是直连ni的节点nj集合,j<i。因此可以稍加改写上面的公式:
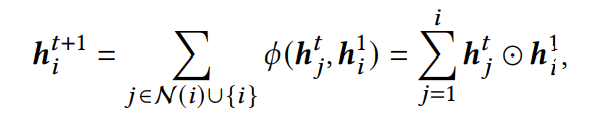
这里的交互学习函数是基本的内交互学习函数。
从上述两个公式可以看出,DAGFM的每个特征交互都和DP图当中的唯一路径匹配。每个k阶特征交互对应从第一层开始的长度为k-1的唯一路径。对状态向量进行求和,所有路径都可以遍历,这也说明**所有特征交互都可以在DAGFM当中被建模**。
对于具有内部和内核交互学习函数的图传播过程,通过将权重分配为全1向量和矩阵可以等同。权重也可以在训练过程中学习,这使得DAGFM能对不同语义信息的特征交互建模。
比如特征:男人、工作日、加拿大、晴天,那么男人×工作日×加拿大的特征交互就对应n11->n22->n33,边代表权重,控制语义强度。
DAGFM传播图示例:
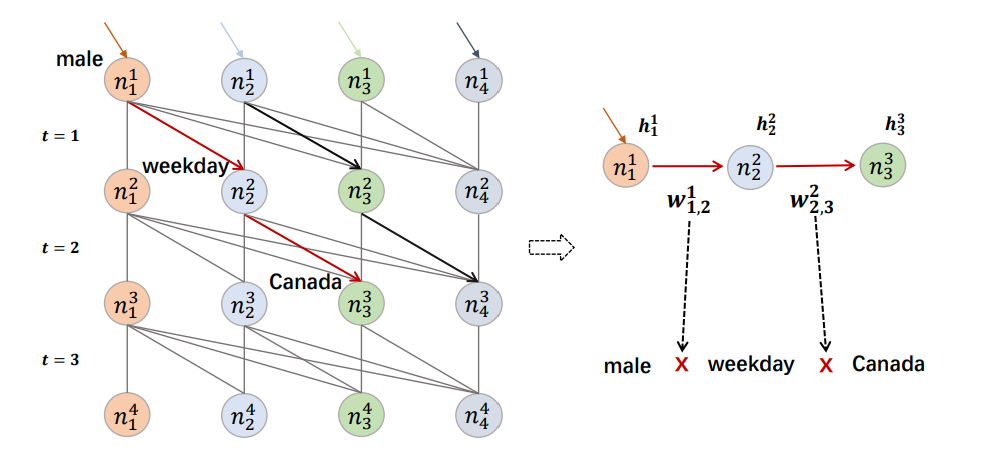
¶知识蒸馏的过程
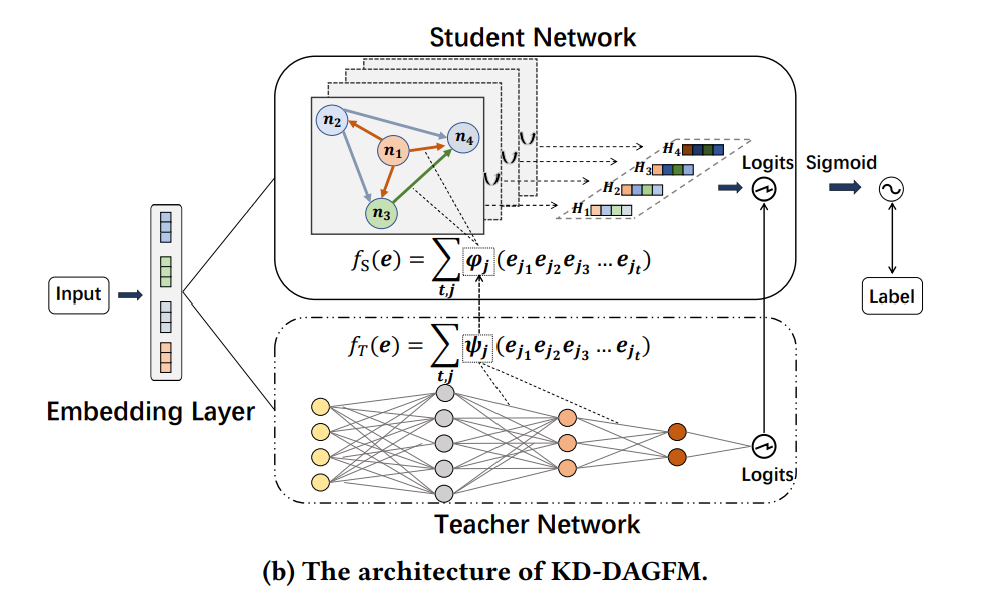
KD-DAGFM的整体架构图如上所示。
在知识蒸馏的过程中,学生网络DAGFM从教师网络学习特征交互的知识。为了保证学生和教师网络的特征空间相同,将教师网络的嵌入层与学生网络共享。
知识蒸馏的损失函数:
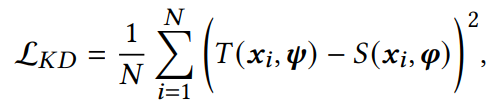
N是训练实例的总数,T和S是学习函数,𝝍 和𝝋分别是教师和学生网络的参数。(其实也就是衡量教师网络和学生网络的效果差距,利用方差的形式)
我们采用交叉熵损失函数进行CTR预测:
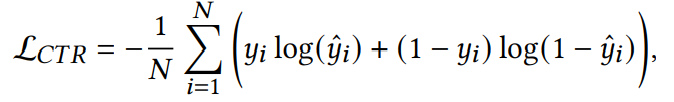
最终优化目标是:
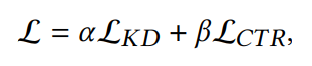
𝛼, 𝛽 是平衡两个损失函数的权重的超参数。
经过知识蒸馏,学生模型可以很好地从教师网络当中学习到有用的特征交互。其实也就是同时从现有的教师模型和结果当中学习。
但是但是
学生的特征嵌入继承自教师,教师在蒸馏过程中没有训练,可能导致欠拟合问题,导致学生模型不理想。为了缓解这个问题,他们微调了学生模型(没有说具体方法)。
以上基本上就把具体的模型和方法全都学完了。
¶实验
接下来就是实验证明KD-DAGFM的效果了。实验当中用了四个真实世界当中的数据集:Criteo、Avazu、MovieLens-1M和微信。
Criteo是最流行的CTR预测基准数据集,包含7天内的用户日志。Avazu包含7天的用户日志,用于Avazu CTR预测比赛。MoviesLens-1M是推荐系统研究中最受欢迎的数据集。
¶学生模型DAGFM的有效性分析
这一小节,旨在证明学生模型DAGFM能达到复杂教师模型的近似无损性能。
一方面和教师模型比,是不是性能无损;另一方面和其他学生模型比较是否性能提升。
-
教师网络。
使用xDeepFM和DCNV2。
-
学生网络。
使用常用的轻型模型FwFM、FmFM、tiny MLP作为学生模型进行比较。对于DAGFM,采用了教师和交互学习函数的最佳组合,CIN和DAGFM-inner和DAGFM-minor。
结果显示,和教师模型相比学生模型DAGFM的复杂度大大降低,和其他学生模型相比,DAGFM的复杂度更低,并且损失也更小。
¶KD-DAGFM的实验结果
接下来就是利用实验证明KD-DAGFM模型在CTR预测任务当中的有效性了。
¶比较方法
- FmFM
- FwFM
- xDeepFM
- DCNV2
- FiBiNet
- AutoInt
- FiGNN
- GraphFM
- ECKD
¶实施细节
参数设置直接看图就好。

¶实验结果
- 深度方法比浅度方法有效,说明了高阶特征交互的重要性
- 显式方法比隐式方法更有效
- 基于图的模型很有竞争力
- 知识蒸馏也非常有效
- KD-DAGFM比DAGFM更有效
KD-DAGFM能够有效地学习高阶特征交互的相互作用,较少的参数也更贴近现实应用。
¶KD-DAGFM的实验分析
本节分析影响模型性能的因素。
¶传播层数的影响
传播层数的影响其实就是特征交互的阶数的影响,传播层数越多,那么特征交互的阶数就越高。
随着层数的增加,模型的性能变得更好,表面学习高阶特征交互信息对于CTR预测的重要性。
¶不同交互学习函数的影响
利用前文提出的外部交互学习函数的DAGFM可以很好地适用于不同的教师模型。
¶通用的蒸馏模型KD-DAGFM+
考虑到教师模型的复杂性(同时学习显性特征和隐性特征的交互),为了有效地从显性和隐性特征交互中提取知识,提出了KD-DAGFM+,在学生模型DAGFM之后附加一个MLP组件(DAGFM所有节点地状态串联起来输入MLP)。KD-DAGFM+实现了近乎无损的蒸馏性能。
¶相关工作
¶特征交互学习
学习特征的交互是CTR预测任务当中的基本问题…
¶图神经网络
¶知识蒸馏
知识蒸馏(Knowledge Distillation,KD)是一种从复杂模型当中提取知识并将其压缩到一个简单模型中的方法
¶总结
本论文提出一个轻量级的知识蒸馏模型KD-DAGFM,该模型是一个用于CTR预测的有向无环图神经网络。学习复杂教师网络当中的特征交互、大大降低计算资源成本。效果甚佳…
这样论文就阅读完了。大致的思路梳理就是:由于特征通常是稀疏的高维度向量,再加上需要学习高阶的特征交互,因此计算量通常比较爆炸。知识蒸馏可以降低模型的复杂度,但是模型精度会下降。因此提出了他们的KD-DAGFM模型。先从CTR任务说起,再说特征交互、交互函数,然后介绍DAGFM的具体工作原理。最后探讨一下性能。DAGFM就是用节点代表特征向量,用边代表特征交互。然后通过多层传播模拟高阶特征交互。
接下来开始尝试复现模型叭~
